


Sometimes, writing tests for a system requires performing certain operations multiple times across different behaviors. These operations can represent the initial configuration, generic actions, etc. JavaScript testing libraries such as Jest, Vitest, and Mocha provide utility methods like beforeEach and afterEach to help developers reduce code duplication. However, these functions can be a Trojan horse! While they are believed to improve test readability, they can easily do more harm than good. So, let's explore how they can negatively impact our tests and what alternatives we have!
Let's take the example of a login page where the button is only clickable if the email and password fields are not empty.
import type { FormEvent } from 'react';
import { useState } from 'react';
interface Props {
onLogin: (email: string, password: string) => void;
}
export function Login({ onLogin }: Props) {
const [email, setEmail] = useState('');
const [password, setPassword] = useState('');
const submit = (event: FormEvent<HTMLFormElement>) => {
event.preventDefault();
onLogin(email, password);
};
const formImcomplete = email === '' || password === '';
return (
<form onSubmit={submit}>
<label htmlFor="email">Email</label>
<input
id="email"
name="email"
type="text"
onChange={event => setEmail(event.target.value)}
/>
<label htmlFor="password">Password</label>
<input
id="password"
name="password"
type="password"
onChange={event => setPassword(event.target.value)}
/>
<button type="submit" disabled={formImcomplete}>Submit</button>
</form>
);
}
Let's start with an initial test that validates the initial state of the form:
describe('Login', () => {
test('should have the submit button initially disabled', () => {
render(<Login />);
expect(screen.getByRole('button', { name: 'Submit' })).toBeDisabled();
});
});
Let's see the test result:

Our test passed, perfect! Let's move on to the next case: When the email field is filled, the button should still be disabled because all fields need to be filled in:
describe('Login', () => {
test('should have the submit button initially disabled', () => {
render(<Login />);
expect(screen.getByRole('button', { name: 'Submit' })).toBeDisabled();
});
test('should have the submit disabled given only the email is filled', () => {
render(<Login />);
const emailInput = screen.getByLabelText('Email');
userEvent.type(emailInput, 'email@email.ca');
expect(screen.getByRole('button', { name: 'Submit' })).toBeDisabled();
});
});
Here we can see that there are two duplicated elements in our tests: the render and the expect. Let's use the beforeEach method to reduce duplication! Although there is an afterEach available for our tests, it is better to keep the assertions within the test itself to maintain some level of coherence. Let's also take this refactoring opportunity to start creating a Domain Specific Language (DSL) for our page.
describe('Login', () => {
beforeEach(() => {
render(<Login />);
});
test('should have the submit button initially disabled', () => {
expect(submitButton()).toBeDisabled();
});
test('should have the submit disabled given only the email is filled', () => {
const emailInput = screen.getByLabelText('Email');
userEvent.type(emailInput, 'email@email.ca');
expect(submitButton()).toBeDisabled();
});
const submitButton = () => screen.getByRole('button', { name: 'Submit' });
});
Let's add the case where the user enters the email first and then the password! Since adding an email is already present in the previous test, we can create a new describe block with its own beforeEach function.
describe('Login', () => {
beforeEach(() => {
render(<Login />);
});
test('should have the submit button initially disabled', () => {
expect(submitButton()).toBeDisabled();
});
describe('when filling the email', () => {
beforeEach(() => {
const emailInput = screen.getByLabelText('Email');
userEvent.type(emailInput, 'email@email.ca');
});
test('should have the submit disabled', () => {
expect(submitButton()).toBeDisabled();
});
describe('and filling the password', () => {
test('should enable the submit button', () => {
const passwordInput = screen.getByLabelText('Password');
userEvent.type(passwordInput, 'password123');
expect(submitButton()).toBeEnabled();
});
});
});
const submitButton = () => screen.getByRole('button', { name: 'Submit' });
});
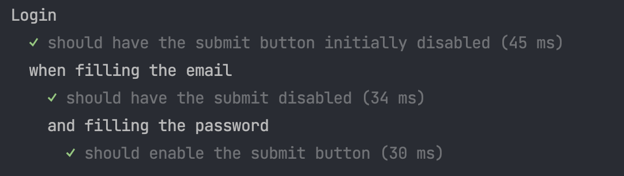
Now we have a test suite that validates the empty form, the form with only one field, and the form with both fields filled in! Although the tests meet the acceptance criteria, we are starting to have scattered tests throughout the entire file. The test names are also suffering the same fate, as we now have to compose the describe blocks with the test function to understand what the test is validating and how. While our test suite is short and simple, imagine a file with 50 tests for a more complex UI! I have seen those in projects, they are not fun to work with...
Indentation reduction through composition
If beforeEach functions are impacting code readability, how can we avoid duplication? Part of the solution has already been presented in the examples above. The beforeEach function is explained by the name of the describe block, which represents the intention of the function. This intention is usually specific to the context of what we are testing, so it could be part of our DSL! If we apply this testing technique to enhance readability, here is what our refactoring plan could look like:
-
Encapsulate the content of beforeEach in a function with a name in the same style as the describe block, creating our DSL.
-
Use the function directly in the tests.
-
Remove the describe block with its beforeEach function and update the test name to make it clearer.
If we only look at the test that validates the button is disabled when only the email field is filled in:
describe('Login', () => {
beforeEach(() => {
render(<Login/>);
});
describe('when filling the email', () => {
beforeEach(() => {
const emailInput = screen.getByLabelText('Email');
userEvent.type(emailInput, 'email@email.ca');
});
test('should have the submit disabled', () => {
expect(submitButton()).toBeDisabled();
});
});
const submitButton = () => screen.getByRole('button', { name: 'Submit' });
});
And if we apply our recipe step by step, we would end up with:
1. Create DSL functions
describe('Login', () => {
beforeEach(() => {
initLogin();
});
describe('when filling the email', () => {
beforeEach(() => {
enterEmail('email@email.ca');
});
test('should have the submit disabled', () => {
expect(submitButton()).toBeDisabled();
});
});
const initLogin = () => render(<Login/>);
const submitButton = () => screen.getByRole('button', { name: 'Submit' });
const enterEmail = (email: string) => {
const emailInput = screen.getByLabelText('Email');
userEvent.type(emailInput, email);
};
});
2. Use DSL functions directly in the test
describe('Login', () => {
beforeEach(() => {});
describe('when filling the email', () => {
beforeEach(() => {});
test('should have the submit disabled', () => {
initLogin();
enterEmail('email@email.ca');
expect(submitButton()).toBeDisabled();
});
});
const initLogin = () => render(<Login/>);
const submitButton = () => screen.getByRole('button', { name: 'Submit' });
const enterEmail = (email: string) => {
const emailInput = screen.getByLabelText('Email');
userEvent.type(emailInput, email);
};
});
3. Rename test and remove useless code
describe('Login', () => {
test('should have the submit disabled when only the email is filled', () => {
initLogin();
enterEmail('email@email.ca');
expect(submitButton()).toBeDisabled();
});
const initLogin = () => render(<Login/>);
const submitButton = () => screen.getByRole('button', { name: 'Submit' });
const enterEmail = (email: string) => {
const emailInput = screen.getByLabelText('Email');
userEvent.type(emailInput, email);
};
});
Now we have a test that contains everything essential for its understanding, and it is no longer scattered everywhere. If we apply this recipe again and again, we would eventually get a test suite that looks like:
describe('Login', () => {
test('should have the submit button initially disabled', () => {
initLogin();
expect(submitButton()).toBeDisabled();
});
test('should have the submit disabled when only the email is filled', () => {
initLogin();
enterEmail('email@email.ca');
expect(submitButton()).toBeDisabled();
});
test('should enable the submit button when both fields are filled', () => {
initLogin();
enterEmail('email@email.ca');
enterPassword('password123');
expect(submitButton()).toBeEnabled();
});
const enterPassword = (password: string) => {
const passwordInput = screen.getByLabelText('Password');
userEvent.type(passwordInput, password);
};
const enterEmail = (email: string) => {
const emailInput = screen.getByLabelText('Email');
userEvent.type(emailInput, email);
};
const submitButton = () => screen.getByRole('button', { name: 'Submit' });
const initLogin = () => render(<Login onLogin={jest.fn()} />);
});

With this test format, it is also clear that our test suite is incomplete! We are missing the test that validates the submit button is disabled when only the password field is filled in. With our new DSL, it is very easy to build our test:
test('should have the submit disabled when only the password is filled', () => {
render(<Login />);
enterPassword('password123');
expect(submitButton()).toBeDisabled();
});
Now we have a complete test suite for the behavior of the submit button in our component.

Helping ourselves understanding
How does it really help with readability? One of the explanations behind this practice comes from the way short-term memory works. It temporarily retains (less than a minute) a limited amount of information (about 4) before it is stored for a longer time in our long-term memory. Overloading short-term memory makes it difficult to grasp the overall understanding of things. In programming, each level of indentation can be seen as a context. In the initial example in this article, we had only 5 contexts for the filled email test: 2 describes, 2 beforeEach, and the test content. After the refactor, we had only 2: 1 describe and the test content. The use of a DSL helps our short-term memory when reading code because it abstracts any information that may not be important for our understanding.
One could see this approach as similar to writing a newspaper article. The essential information of the news is located in the headline and the page header. If we are interested in more detail about the news, we scroll down the page to see the content. It's similar when we read our tests:
- The test name is the headline of our article.
- The test content is the page header.
- The methods of our DSL are the details.
With the use of beforeEach, it's like several articles are jumbled together on the same page instead of being presented one after another.
Multiple problems, multiple solutions
In software development, I have often heard the phrase: "We use X solution in this place, why can't we just reuse it here too!" To that, I say: "Not so fast!" This solution often boils down to a technology choice. In the React ecosystem, Redux is the perfect example. The lack of standards and recommendations on how to use this library has led many developers to use it everywhere without considering whether it's the right solution. Over time, performance issues arise in projects following this approach, in addition to increasing code and test complexity.
The same thing happens with beforeEach. Simply because it exists in the library doesn't mean it should be used in every test. An example of appropriate usage for beforeEach and afterEach methods is when there is a need for global configuration or resetting.
describe('LocalDB', () => {
beforeAll(() => {
setupDB();
});
afterEach(() => {
clearDB();
});
afterAll(() => {
closeDB();
});
test('given no value, should throw when trying to get a value by id', () => {
// ...
});
// ...
});
Let's consider an extreme scenario for a moment. We have a test suite that uses beforeEach to remove logic from a test. Jest provides us with afterEach, so why not use it as well?
describe('Login', () => {
beforeEach(() => {
initLogin();
});
test('should have the submit button initially disabled', () => {});
afterEach(() => {
expect(submitButton()).toBeDisabled();
});
});

As we can see, this test is considered valid! Is it well structured? Not really... Are there cases where we would want an expect statement in the afterEach? Certainly! A technical validation that we want to perform after each test, such as ensuring an object is not mutated, is a good use case for afterEach here. The usage of these test functions remains contextual.
Conclusion
By avoiding the use of beforeEach methods in our tests, combined with the DSL approach, we can greatly simplify our tests by consolidating everything necessary for the test while avoiding unnecessary code duplication.
This article is heavily inspired by two articles by Kent C Dodds, the creator of Testing Library:
Et si votre projet était subventionné?
Vous pourriez financer jusqu'à 50% de votre projet d'intelligence artificielle grâce aux programmes de subventions.

